

At Compare The Market, we have an internal AI tool that automatically reviews merge requests. The goal is to speed up the time it takes for developers to receive feedback on their code and increase MR throughput across the organisation. Developers get an intelligent first-pass review within minutes of opening an MR.
It works well, but we wanted it to work better. The reviewer was leaning on the side of conservatism, where we often saw false positives in bug detection due to the limitations of reviewing code changes in isolation. We wanted to provide the reviewer with an understanding of how the change sits within the broader system. For example, a deleted function might seem like dead code, unless you know it’s called dynamically from another service.
At this point we faced a fundamental architectural decision: How should the agent retrieve context about the codebase?
We had two main options:
GKG (GitLab Knowledge Graph): A code analysis engine that uses Tree-sitter AST parsing (via gitlab-code-parser) to build a structured knowledge graph of code entities and relationships, stored in a Kuzu graph database. Enabling precise queries like “find all callers of this function” or “show me the class hierarchy”
RAG (Retrieval-Augmented Generation): A vector similarity search approach that chunks code, creates embeddings, and retrieves semantically similar code snippets.
We chose GKG based on intuition – our hypothesis was that code review requires structural understanding of code relationships, not just semantic similarity. When reviewing a change to a function, you need to know what calls it, what it calls, and how it fits into the broader architecture. RAG excels at finding “similar” code, but similarity isn’t the same as relevance for code review.
This article validates that intuition. Through rigorous evaluation using MLflow on Databricks, we compared four approaches and found that GKG outperforms RAG on the metrics that matter most for code review quality. The data confirms our architectural decision was correct.
We evaluated four distinct configurations:
What is GKG?
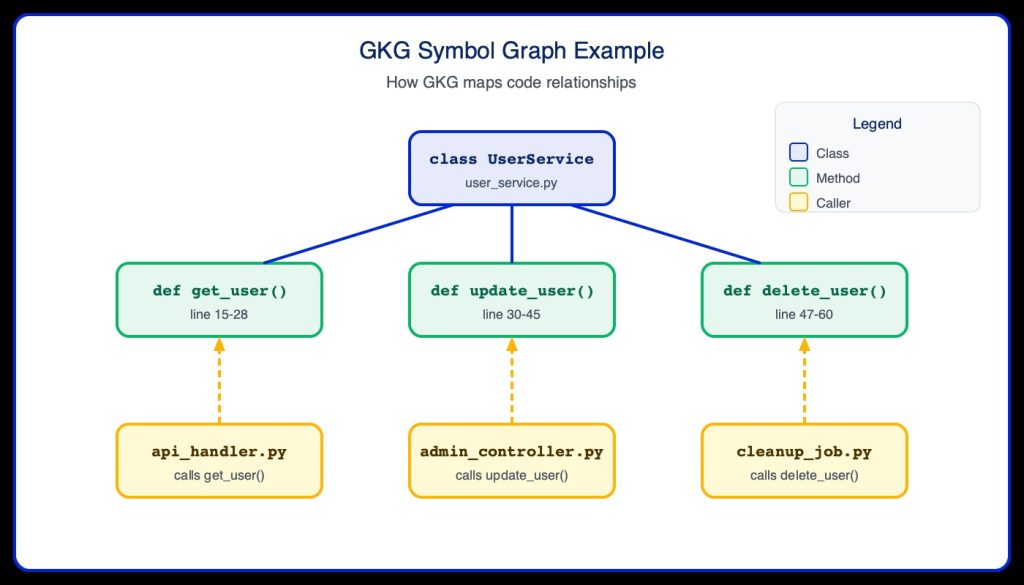
Last year, GitLab introduced a beta version of an MCP (Model Context Protocol) server called the GitLab Knowledge Graph (GKG). The API indexes the repository and builds a structured, queryable representation of the codebase. It maps dependencies onto nodes in a graph, understands function definitions and their usage, traces inheritance hierarchies, and captures cross-references between modules.
The result is a semantic map of your code – not just a list of files, but a web of relationships. Through the tools provided by the MCP server, AI agents can query this graph in real time:
“Where is this function called?”
“What classes inherit from this interface?”
“What would be affected if I changed this method signature?”
Our Sidecar Integration
Because GKG was still in beta and not yet available as a native GitLab CI/CD feature, we built a separate sidecar service – a lightweight Docker container that wraps the official GKG binary and runs alongside our reviewer in the CI pipeline.
The Workflow
Index – When a merge request pipeline kicks off, the sidecar container mounts the project source and indexes the full codebase, building the knowledge graph from scratch.
Serve – Once indexed, it starts the GKG MCP server on a local port, exposing a set of tool calls.
Query – Our AI reviewer connects to the MCP server and uses these tools as part of its review workflow.
How the Knowledge Graph Works
GKG builds a symbol graph — a structured representation of your codebase where nodes represent code entities (classes, functions, variables) and edges represent relationships (calls, inherits, imports).
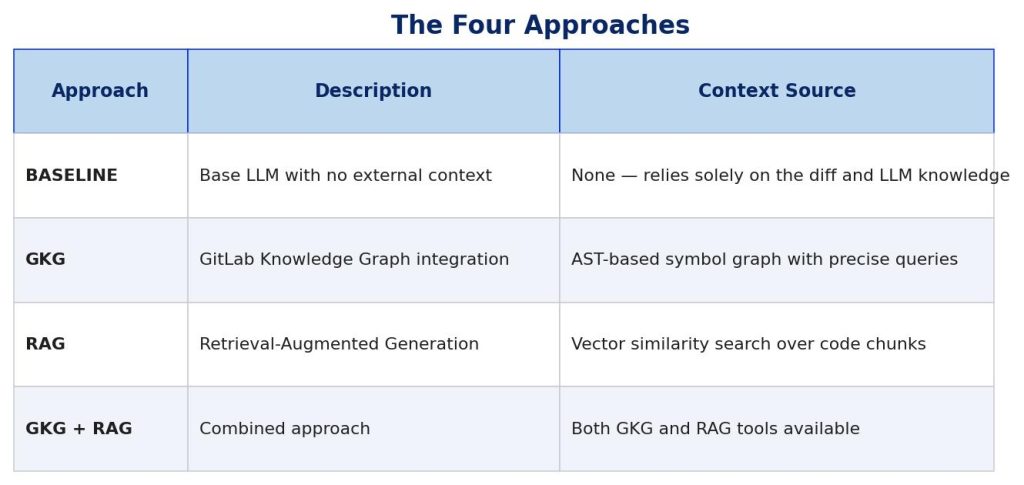
The Indexed Project Graph
When GKG indexes a repository, it creates an interactive graph visualisation showing the entire codebase structure. Here’s what the indexed graph might look like for an example project:
Each node type represents a different code entity:
Orange (Directory) – Folder structure of the repository.
Green (File) – Individual source files.
Purple (Definition) – Classes, functions, and methods defined in the code.
Blue (Imported Symbol) – External dependencies and imports.
The edges (lines) show relationships: which files contain which definitions, which functions call other functions, and which modules import which symbols.
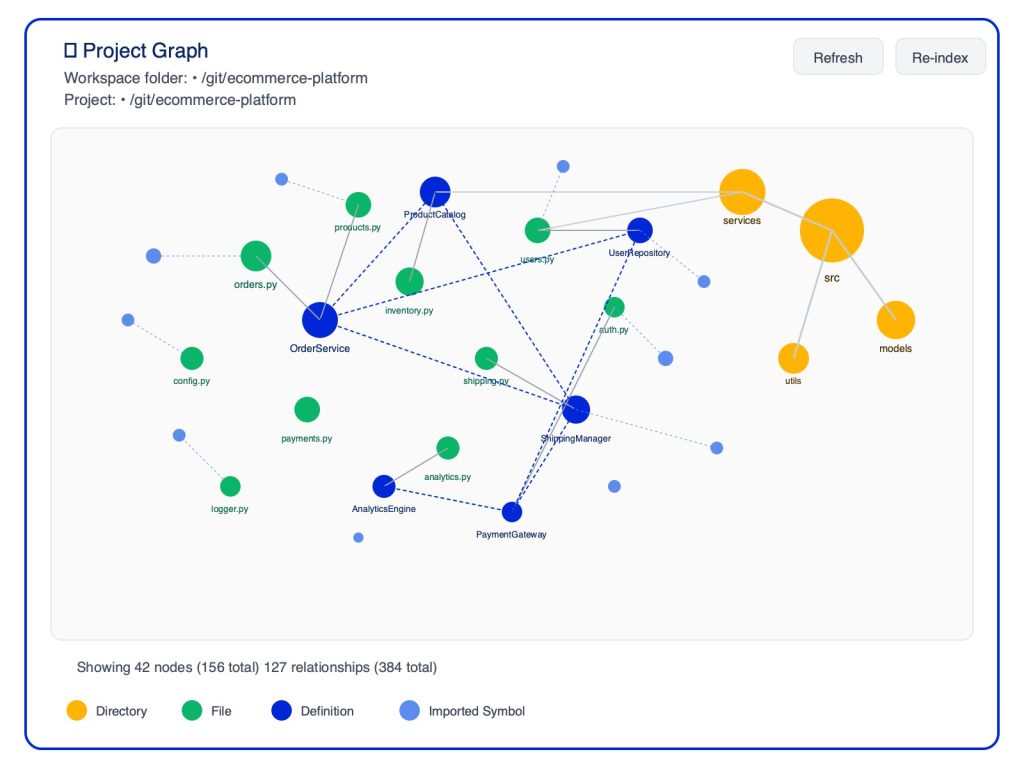
Example: Symbol Graph Structure
Consider a simple UserService class. GKG maps it as a graph showing the class, its methods, and all the files that call those methods:
Example: Querying the Graph
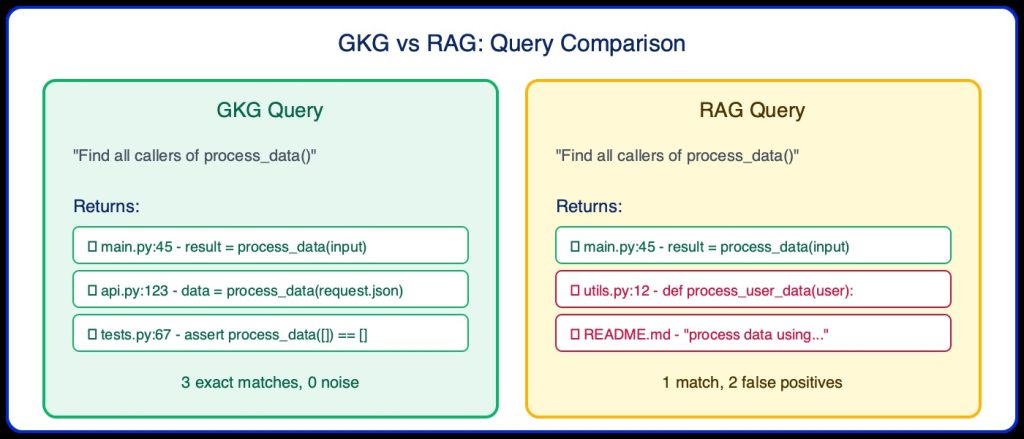
When the AI reviewer needs to understand the impact of a change, it queries GKG. For example, if someone modifies validate_input(), the agent asks: “Who calls this function?”

This precise information allows the reviewer to assess whether a change to validate_input() could break any of these three callers – something impossible with just the diff alone.
Now the reviewer is able to utilise GKG to query the knowledge graph to verify the initial concerns our discovery agent identifies against the wider codebase. For example, if a change looks like it might break a contract, the agent traces the dependency chain to verify before reporting it as an issue.
By verifying initial concerns against the actual structure of the codebase, the reviewer produces more accurate, more consistent feedback, and critically, fewer false positives in bug detection.
Our RAG implementation uses LlamaIndex for intelligent code chunking and OpenAI embeddings for vector similarity search.
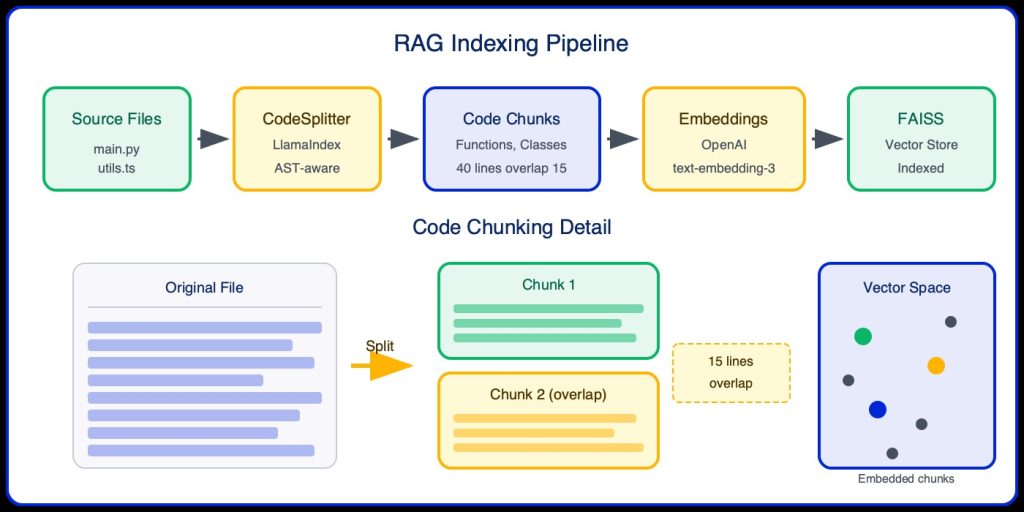
The indexing pipeline:
Source Files: Scan repository for code files (.py, .js, .ts, etc.).
CodeSplitter: LlamaIndex AST-aware chunking.
Code Chunks: Semantic units (functions, classes) with overlap.
Embeddings: OpenAI text-embedding-3-small.
FAISS: Vector store for fast similarity search.
The key component of our RAG implementation is the CodeSplitter from LlamaIndex. Unlike naive text chunking, CodeSplitter uses a graph-first approach: it first builds an AST (Abstract Syntax Tree) graph of the code, then uses this structural understanding to create semantically meaningful chunks.
Step 1: Build the AST Graph
Before any chunking happens, Tree-sitter parses the source code into a hierarchical graph structure. This graph represents the syntactic structure of the code – functions, classes, methods, and their relationships.
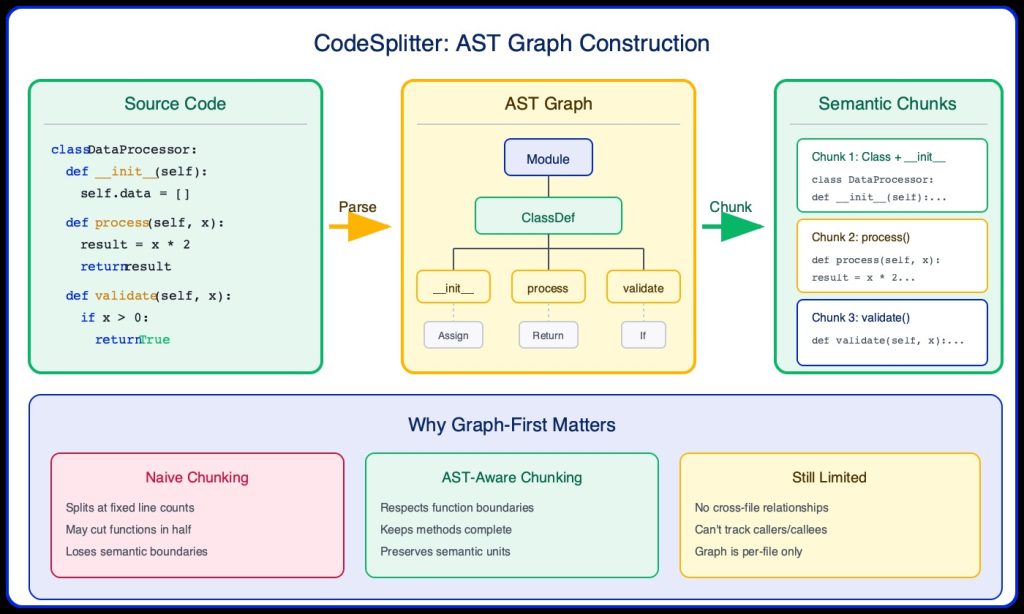
Step 2: Traverse Graph to Create Chunks
Once the AST graph is built, CodeSplitter traverses it to identify semantic boundaries. Instead of blindly splitting at line 40, it finds natural break points:
Function boundaries: Each function becomes a chunk (or multiple if large).
Class boundaries: Class definitions with their methods.
Logical groupings: Related code stays together.
The Fundamental Limitation: RAG relies on semantic similarity in vector space, which works well for natural language but has inherent limitations for code:
1. No Symbol Resolution
RAG cannot distinguish between a function definition and a function call with the same name. It treats def process_data() and process_data() as semantically similar without understanding the relationship.
2. No Reference Tracking
When reviewing a change to a function, RAG cannot reliably find all callers of that function. It may return semantically similar but unrelated code.
3. Chunk Boundary Issues
Even with AST-aware chunking, important context may be split across chunks. A function’s signature might be in one chunk while its implementation is in another.
4. Precision vs Recall Trade-off
RAG optimises for semantic similarity, which may surface “related” code that isn’t actually relevant to the review. This can overwhelm the LLM with noise.
Evaluating a generative AI reviewer is fundamentally different from evaluating a classifier or a search engine. A code review has no canonical correct output – two expert engineers reviewing the same merge request will write different, equally valid feedback. This means standard accuracy metrics don’t apply, and simple text comparison is meaningless.
The challenge compounds when you consider that quality is multidimensional. A review might identify the right risks but overstate severity. It might be perfectly calibrated in scoring but miss the one critical issue. It might surface the correct concern but point to the wrong line of code. Each of these failure modes matters independently, and optimising for one can actively degrade another. This is what makes rigorous AI evaluation hard: the outputs are open-ended, non-deterministic, and semantically rich.
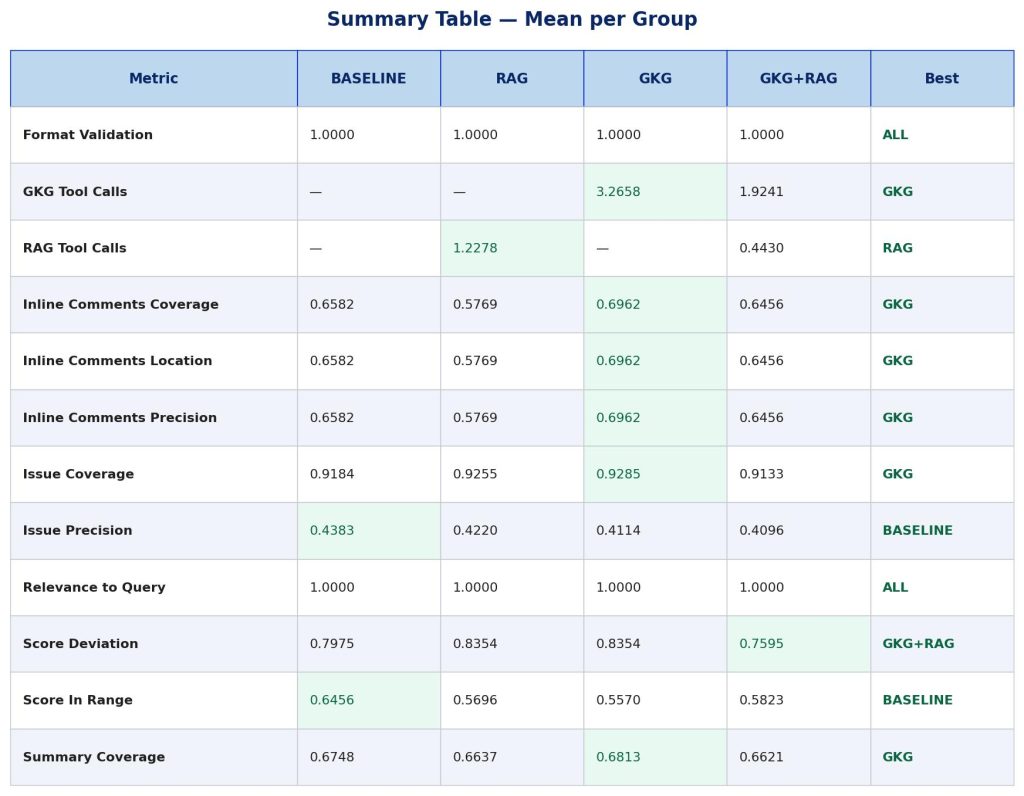
To evaluate reliably, we need a fixed reference point. We constructed a golden dataset of 79 real merge requests from our internal repositories, a structured benchmark where each entry carries expert-annotated ground truth across multiple dimensions:
Expected summary points – the key changes and their implications.
Expected issues – risks, bugs, and concerns that a thorough reviewer should surface.
Expected inline comments – specific defects, tied to exact file locations and code lines.
Expected score range – the range of severity scores a calibrated human reviewer would assign.
Constructing this dataset required deliberate effort. The MRs represent real production complexity, covering different codebases, change sizes, and types, rather than easy cases favoring any approach. Each entry was annotated with a consistent rubric defining a thorough, well-calibrated review: identifying the right issues, flagging the correct lines, and assigning a severity score reflecting genuine impact.
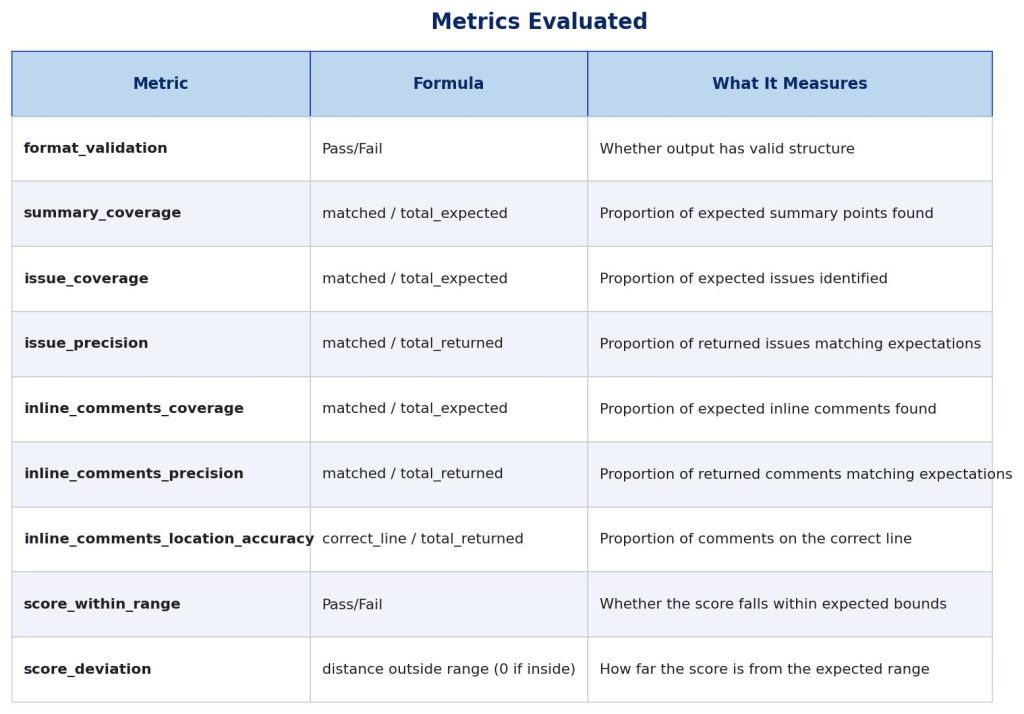
All four approaches (Baseline, GKG, RAG, GKG+RAG) were evaluated on the same 79 entries. Each generated review was assessed across five core quality dimensions:
Coverage – How many expected summary points, issues, and inline comments appear in the output? A review missing a critical bug scores low here regardless of addressing other issues.
Precision – Of everything the reviewer surfaced, how much was actually warranted? This penalizes over-generation: a review flagging 20 issues when 5 were expected may have good coverage but poor precision, indicating a noisy, unreliable reviewer.
Inline comment location accuracy – Code review is inherently spatial. It’s not sufficient to identify a problem in prose. It needs to be attached to the correct file and anchored to the relevant code change. We verified this separately from semantic correctness.
Score calibration – The reviewer assigns a severity score from 0 – 10. We measured whether that score fell within the range a human would consider reasonable. This matters for developer trust: a reviewer that consistently over or under penalises loses credibility quickly.
Structural validity – a schema check ensuring required fields are present and well-formed (e.g., non-empty summary and score, inline comments include required fields). All approaches consistently passed this check in our runs.
For nuanced criteria, such as whether a generated summary “covers the same point” as a reference, text matching fails. “The function signature changed” and “the method contract was modified” are semantically equivalent but lexically distant.
We used an LLM as an automated judge. Given the reference expectations and generated output, the judge counted how many expected points were covered, evaluating intent and meaning, not phrasing. This LLM-as-judge technique is standard in generative AI evaluation and enables semantic scoring at the scale of thousands of data points without manual review for each result.
All metrics are evaluated against a golden dataset – a curated set of expected outputs for each MR. This means results are heavily dependent on the quality and completeness of the golden set expectations.
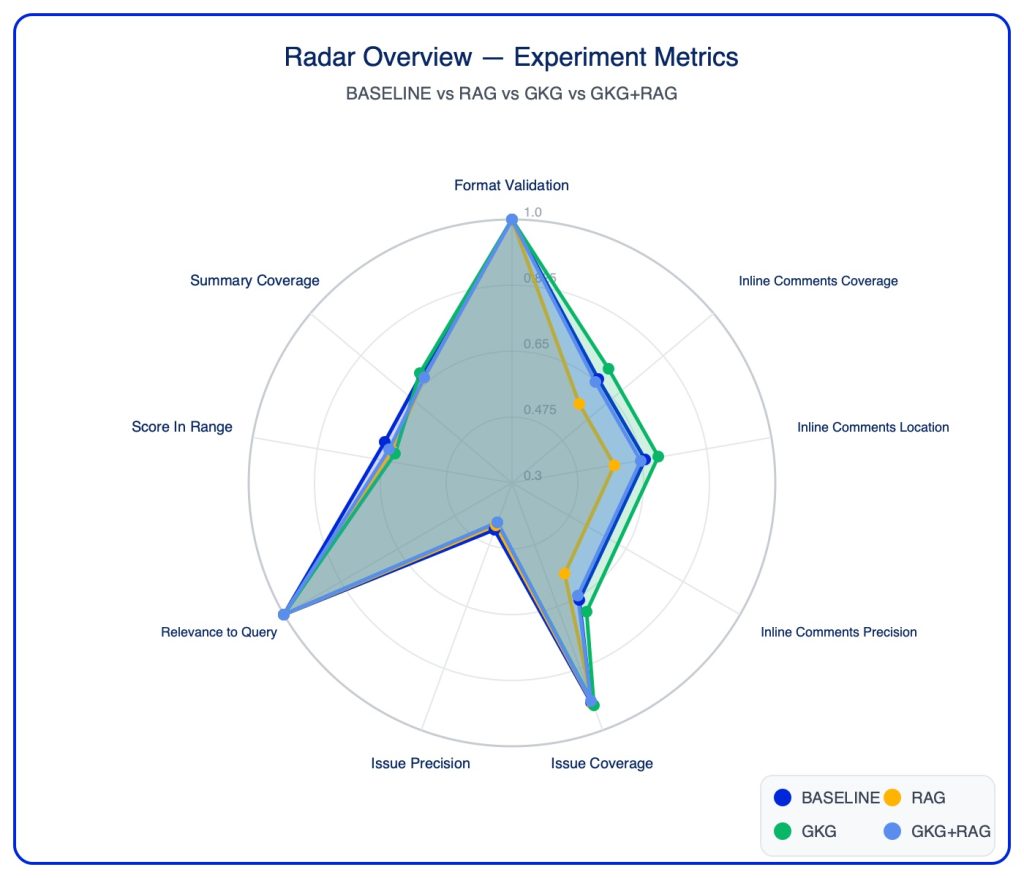
Finding 1: GKG Outperforms RAG for Code Review
GKG consistently outperformed RAG across coverage metrics:
Inline Comments Coverage: GKG 0.696 vs RAG 0.577 (+21%).
Issue Coverage: GKG 0.929 vs RAG 0.926 (marginal).
Summary Coverage: GKG 0.681 vs RAG 0.664 (+3%).
GKG’s AST-based symbol resolution enables precise identification of callers, references, and definitions — exactly what’s needed for thorough code review.
Finding 2: RAG Performs Worse Than BASELINE
Surprisingly, RAG underperformed the baseline (no context tools) on nearly all metrics:
Inline Comments Coverage: RAG 0.577 vs BASELINE 0.658 (-12%).
Summary Coverage: RAG 0.664 vs BASELINE 0.675 (-2%).
Score In Range: RAG 0.570 vs BASELINE 0.646 (-12%).
Issue Precision: RAG 0.422 vs BASELINE 0.438 (-4%).
Root causes identified:
Noise introduction: Vector similarity retrieves code that “looks similar” but isn’t relevant, distracting the model.
False positives: RAG finds process_user_data when searching for process_data.
Per-file limitation: RAG’s AST chunking is per-file only – no cross-file relationship understanding.
Distraction effect: Additional context can mislead rather than help when it’s not precisely relevant.
Finding 3: Understanding Issue Coverage vs Precision
BASELINE achieved the highest issue precision (0.438) while GKG had the lowest (0.411). However, this requires careful interpretation:
BASELINE generates fewer issues: Higher precision often means fewer total issues returned, not more accurate issues.
GKG finds more issues: Lower precision may indicate GKG is finding legitimate issues not anticipated in the golden set.
Golden set limitation: Precision penalises finding valid issues that weren’t in the expected list.
Key insight: A reviewer that generates fewer issues will naturally have higher precision (fewer chances to “miss” the golden set), but this doesn’t mean it’s more accurate — it may simply be more conservative.
Finding 4: GKG Uses More Tool Calls Effectively
GKG averaged 3.27 tool calls per review vs RAG’s 1.23 calls. The additional calls translate to better coverage because:
get_references finds exact callers/callees.repo_map provides structural overview.
Each call returns precisely relevant code, not semantic approximations.
Finding 5: GKG outperforms GKG + RAG
GKG+RAG uses fewer tool calls than either GKG or RAG alone (1.92 GKG + 0.44 RAG), but doesn’t show improved metrics over the individual approaches. GKG alone still performs best on summary coverage and issue coverage.
Finding 6: Results Depend Heavily on the Golden Dataset
All metrics are evaluated against a curated golden dataset of expected outputs. This introduces important limitations:
Incomplete expectations: The golden set may not capture all valid issues a reviewer could find
Subjectivity: What constitutes a “matching” issue is determined by an LLM judge, introducing variability
Bias towards conservative reviewers: Reviewers that generate fewer outputs will score higher on precision even if they miss valid findings
Coverage ceiling: Coverage can only reach 100% if the reviewer finds exactly what was expected — novel valid findings don’t improve coverage
These results should be interpreted as alignment with expectations, not absolute measures of review quality.
For AI Code Review Tools:
1. Use AST-based tools like GKG for code context retrieval – they provide the precision needed for structural queries.
2. Avoid RAG for symbol resolution tasks – vector similarity cannot reliably distinguish definitions from calls, or find exact references.
3. Consider BASELINE for simple MRs – the diff alone is often sufficient, and adding noisy context can hurt.
4. Measure before adding context – more context isn’t always better; precision matters as much as coverage.
While RAG underperformed for code review, it may still be valuable for:
Documentation search: Finding relevant README sections or comments.
Conceptual queries: “How does authentication work in this codebase?”.
Pattern discovery: Finding code that implements similar concepts (not exact symbols).
Fallback option: When GKG is unavailable or for languages without AST parser support.
Beyond quality metrics, production deployments must consider latency (how long each review takes) and cost (token consumption). We measured both across all 79 MRs for each approach.
Latency Analysis
Review duration varies significantly based on the approach used:
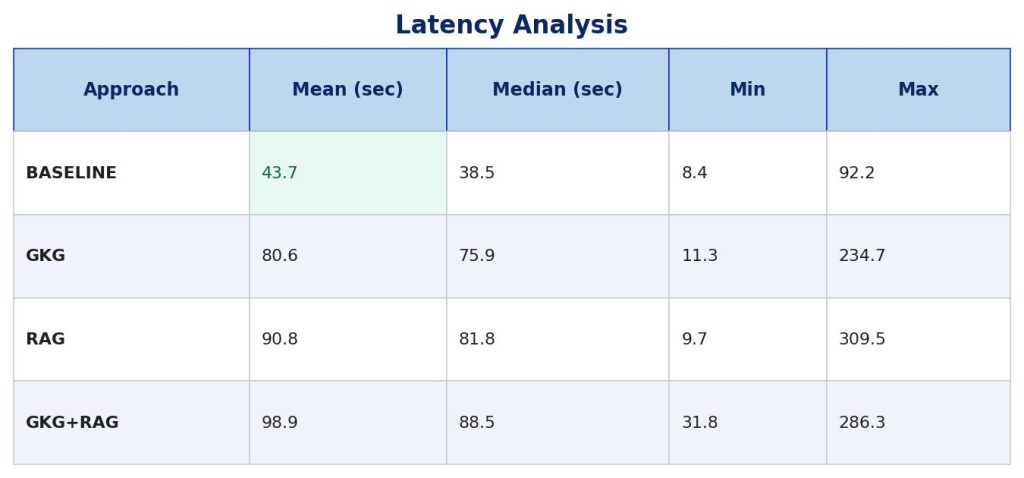
Latency Insights
BASELINE is 2x faster than augmented approaches (~44s vs ~80-99s).
GKG is faster than RAG (80.6s vs 90.8s) despite making more tool calls (3.27 vs 1.23) — local graph traversal outperforms network-based vector search.
GKG+RAG is slowest at ~99s, combining overhead of both methods with no quality benefit.
High variance exists across MRs (8s to 310s) depending on complexity and context needs.
Cost Analysis (Token Usage)
Token consumption directly impacts operational costs. We measured input and output tokens for each approach:
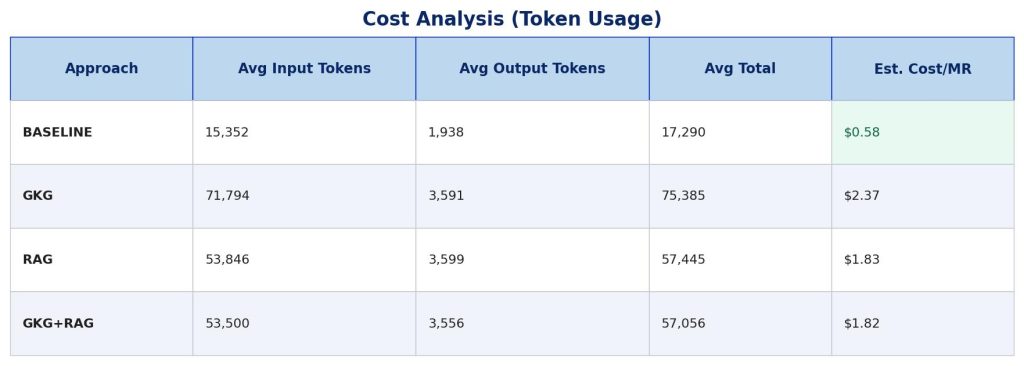
Cost estimates are illustrative, based on GPT-4 pricing ($0.03/1K input tokens, $0.06/1K output tokens), and intended to show relative differences between approaches rather than exact costs.
Cost Insights
BASELINE is 4x cheaper than augmented approaches ($0.58 vs $1.82-$2.37).
GKG is most expensive at $2.37/MR due to richer context from code graph queries.
GKG+RAG uses fewer tokens than GKG alone (57K vs 75K) — the combined approach is more selective, but this doesn’t translate to better quality.
Output tokens are similar across all approaches (~2-4K), indicating review length is consistent regardless of context method.
Cost-Quality Trade-off
When considering both quality and cost, the picture becomes clearer:
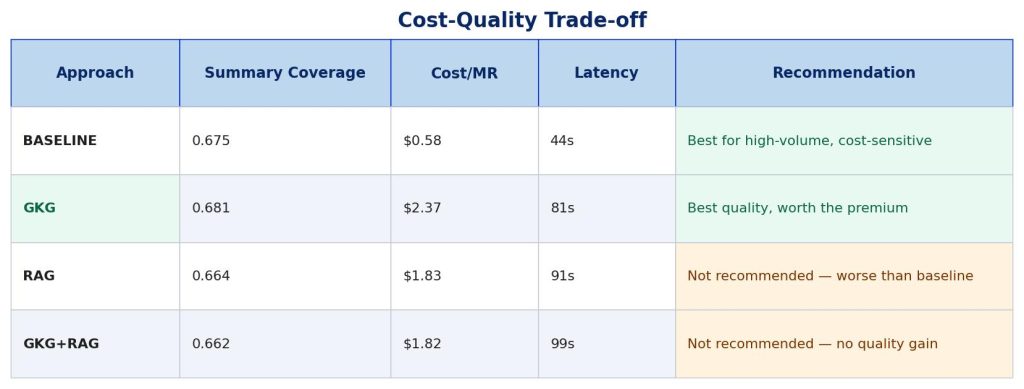
Bottom Line: If cost is a concern, use BASELINE – it’s 4x cheaper and faster with acceptable quality. If quality is paramount, use GKG – the 4x cost increase delivers measurable improvements. Avoid RAG and GKG+RAG – they cost more than baseline without delivering better results.
Our empirical evaluation across 79 merge requests confirms that RAG is not ideal for code review context retrieval. RAG performed worse than the baseline on nearly all metrics – including inline comments coverage, summary coverage, and score accuracy – demonstrating that adding noisy context can be counterproductive.
The structural nature of code – with its precise symbol definitions, references, and relationships – requires tools that understand code structure, not just semantic similarity. GKG’s AST-based approach provides the precision needed for effective code review, enabling the AI to accurately identify callers, understand function signatures, and trace code relationships.
From a cost-efficiency perspective, GKG justifies its 4x cost premium through measurable quality improvements. RAG, however, costs 3x more than baseline while delivering worse results – a clear anti-pattern for production deployments.
Important Caveats
These results should be interpreted with the following limitations in mind:
Golden set dependency: All metrics measure alignment with a curated set of expected outputs, not absolute review quality.
Precision interpretation: Higher precision may indicate fewer issues generated rather than more accurate issues.
LLM judge subjectivity: Semantic matching introduces variability in what counts as a “match”.
Sample size: 79 MRs provides directional guidance but may not capture all edge cases.
Key takeaway: For AI code review tools, invest in AST-aware code intelligence (like GKG) rather than relying on vector similarity search. When GKG isn’t available or cost is constrained, the baseline (diff-only) approach often outperforms RAG at a fraction of the cost.
This evaluation was a starting point, not an endpoint. With GKG validated as the right foundation, the focus shifts from which approach to how well.
Refining the reviewer with real developer signal. The evaluation is grounded in expert-annotated ground truth, but the ultimate measure of quality is whether developers find the feedback useful. The next step is closing that loop – sampling reviews across teams and gathering structured ratings from the engineers who received them. This turns the evaluation from a one-off experiment into a continuous feedback system.
GKG going GA. GKG is currently in beta, running as a sidecar that re-indexes the codebase on every pipeline run. When GitLab ships it as a native CI/CD feature with persistent indexing, the latency overhead drops significantly – making GKG viable at higher MR volumes without the current infrastructure cost. That’s when the cost story changes, and when wider rollout becomes the obvious next step.
Whatever your specialist area, wherever you are in your journey, we’d love to hear from you.

